이 글은 우아한 형제들 콘서트에서 이동욱님의 영상을 보고 정리를 위한 글입니다.
이 글에 작성된 예시는 모두 Github에 올려두었습니다.

Group By 최적화
Mysql 사용 시 index가 걸려있지 않는 컬럼을 group by 할 경우 file sort가 발생합니다.
Index가 걸려있지 않는 경우
select *
from house
group by name
Index가 걸려있는 경우
select *
from house
group by id
file sort가 발생하면 성능이 떨어질 수 밖에 없습니다. 이 경우 order by 절에 null을 넣으면 file sort가 발생하지 않습니다.
select *
from house
group by name
order by null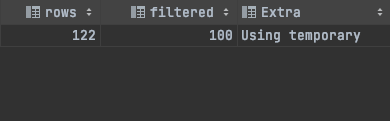
하지만 안타깝게도 Querydsl-JPA 에서는 order by 에 null을 할당할 수 없습니다.

쿼리에 order by 절에 null을 세팅하는 것과 동일하게 Querydsl을 사용하려면 OrderSpecifier 를 상속받아 사용하면 됩니다. 그리고 order by 절에 사용하면 됩니다.
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
public OrderByNull(Order order, Expression target, NullHandling nullhandling) {
super(order, target, nullhandling);
}
public OrderByNull(Order order, Expression target) {
super(order, target);
}
private OrderByNull() {
super(Order.ASC, NullExpression.DEFAULT, NullHandling.Default);
}
}public List<House> findByHouseGroupByNameNotFileSort() {
return queryFactory
.selectFrom(house)
.groupBy(house.name)
.orderBy(OrderByNull.DEFAULT) // use
.fetch();
}
커버링 인덱스
커버링 인덱스는 쿼리의 모든 절에서 사용하는 컬럼이 인덱스에 포함된 상태를 말합니다. B-Tree 인덱스를 스캔하는 것만으로도 원하는 데이터를 조회할 수 있습니다. 이 말은 곧 데이터 블록을 읽지 않아도 되기 때문에 쿼리의 성능을 향상 시킬 수 있습니다.
B-Tree란?
Index의 여러가지 구조중 가장 보편적으로 사용되는 기법입니다.
- Binary Search Tree에서 개선 된 기법
- 인덱스 레코드로 컬럼이 위치한 주소값을 찾아 빠르게 내는 기법
// 인덱스 커버링 적용
// id는 Private key 이다.
// name은 index 이다.
select id
from house
where name = ''
group by id
위 쿼리를 explain하면 Using index for group-by를 확인할 수 있습니다. 즉 인덱스 커버링이 적용되었다는 것을 알 수 있습니다.

그럼 보편적으로 인덱스 커버링 쿼리 사용하는 사례를 살펴보고 Querydsl-JPA에 적용하는 방법을 알아보겠습니다.
select s.*
from staff s
join (
select id // 인덱스 커버링 적용
from house
where name = '강남집'
) h on s.house_id = h.id
안타깝게도 위 쿼리와 똑같은 Querydsl은 작성할 수 없습니다. 이유는 JPQL은 from절에 서브쿼리를 작성할 수 없기 때문입니다. 그리하여 커버링 인덱스 조회를 나눠서 작성합니다.
public List<Staff> findByCoveringIndex(String name) {
List<Long> houseIds = queryFactory // 커버링 인덱스 적용
.select(house.id)
.from(house)
.where(house.name.eq(name))
.fetch();
if (houseIds.isEmpty()) {
return new ArrayList<>();
}
return queryFactory
.selectFrom(staff)
.join(staff.house, house)
.where(house.id.in(houseIds)) // 조회된 id 리스트 적용
.fetch();
}Update
무분별한 DirtyChecking은 피하는 것이 좋습니다.
예시로 아래와 같은 코드를 실행하면 update를 House 객체만큼 실행할 것 입니다.
// bad example
@Transactional
public void badUpdate() {
List<House> houses = houseRepository.findAll();
for (House house : houses) {
house.changeAddress("강남구 완전 중심");
}
}
일괄적으로 업데이트 할 경우에는 1번의 update문으로 처리하는 것이 성능적으로 좋습니다.
@Transactional
public Long updateAddressByName(String name) {
return queryFactory
.update(house)
.set(house.address, "대박 중심")
.where(house.name.eq(name))
.execute();
}
결론
DirtyChecking
- 실시간 비즈니스 처리
- 실시간 단건 처리
Querydsl.update
- 대량의 데이터를 일괄로 update 처리
'Develop > spring-data' 카테고리의 다른 글
| [Querydsl-JPA] 자주 사용하는 기능 정리 (Kotlin) (3) | 2021.05.10 |
|---|---|
| Querydsl Join Table Sort 적용 ( 번외로 Pageable와 비슷한 것을 구현해보자! ) (0) | 2021.03.14 |
| [Querydsl] 성능개선 - 2편 ( N + 1 ) (0) | 2021.02.01 |
| [Querydsl] 성능 개선 1편 (0) | 2021.01.29 |
| [Querydsl-JPA] Querydsl JPA를 사용하며.. "*" 아스타리스크 사용방법 (0) | 2020.12.20 |