[Kafka] 컨슈머 리밸런싱 원인과 줄이는 법: CooperativeStickyAssignor, static membership, 파티션 할당 전략
![[Kafka] 컨슈머 리밸런싱 원인과 줄이는 법: CooperativeStickyAssignor, static membership, 파티션 할당 전략](https://blog.kakaocdn.net/dna/pQgVL/dJMcajiaFWN/AAAAAAAAAAAAAAAAAAAAAMOjgZfbTpQWOJ2QjEup26JEZmAvClM-N8xHU3yIcH8A/img.png?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1782831599&allow_ip=&allow_referer=&signature=IjtPgy9XHU4FJVD45%2FUQQwNqCkQ%3D)
[Kafka] 컨슈머 리밸런싱 원인과 줄이는 법: CooperativeStickyAssignor, static membership, 파티션 할당 전략
리밸런싱은 컨슈머 그룹이 파티션을 다시 나눠 갖는 과정이에요. 자주 일어나면 그동안 메시지 처리가 멈추고 중복까지 생겨요. 그래서 리밸런싱을 이해하고 빈도를 줄이는 게 컨슈머 안정성의 핵심이에요.
컨슈머 그룹과 리밸런싱이 뭔지에서 시작해 언제 일어나는지, 왜 비싼지, eager와 cooperative 방식의 차이, 파티션 할당 전략(Assignor) 네 가지, 리밸런싱을 줄이는 구체적인 방법, 자주 만나는 문제 순으로 짚어요. 컨슈머 동시성과 파티션의 관계는 @KafkaListener 컨슈머 설정 글에서 먼저 다뤘어요.
01. 컨슈머 리밸런싱이 뭔가요
같은 group.id를 쓰는 컨슈머들은 하나의 컨슈머 그룹을 이뤄요. 토픽의 파티션은 이 그룹 안에서 나눠 할당되고, 한 파티션은 그룹 안에서 한 컨슈머만 소비해요. 멤버가 바뀌면 이 분배를 다시 해야 하는데, 그게 리밸런싱이에요.

리밸런싱은 그룹 코디네이터(브로커 중 하나)가 주관해요. 멤버가 바뀌면 코디네이터가 모든 멤버에게 "다시 나누자"고 알리고, 새 할당이 정해질 때까지 그룹이 잠시 멈춰요.
02. 리밸런싱은 이럴 때 일어나요
멤버 구성이 바뀌는 모든 순간이 트리거예요. 대표적인 경우는 이래요.
- 컨슈머 추가/제거 — 스케일 아웃, 배포, 인스턴스 종료. 배포 때마다 내려갔다 올라오면서 두 번씩 일어나기 쉬워요.
- 컨슈머 추방 (heartbeat 끊김) —
session.timeout.ms안에 heartbeat가 안 오면 죽은 걸로 봐요. heartbeat는 백그라운드 스레드가heartbeat.interval.ms주기로 보내요. - 컨슈머 추방 (처리 지연) —
max.poll.interval.ms안에 다음poll()로 못 돌아오면 추방돼요. 처리가 너무 오래 걸릴 때 생겨요. - 토픽 파티션 수 변경 — 파티션을 늘리면 재분배가 필요해요.

두 추방 기준을 헷갈리면 진단이 산으로 가요. heartbeat는 "살아는 있다", poll은 "실제로 일하고 있다"를 뜻하는 서로 다른 신호예요. heartbeat는 별도 스레드가 보내니, 처리 로직이 외부 API에 묶여 있어도 heartbeat는 멀쩡히 나가요. 그래서 "프로세스는 분명 살아 있는데 추방됐다"면 거의 항상max.poll.interval.ms쪽이에요. 이때session.timeout.ms를 늘리는 건 엉뚱한 데를 고치는 거예요.
03. 리밸런싱은 왜 비싼가요 (eager 방식)
기본 리밸런싱 방식(eager)은 stop-the-world예요. 리밸런싱이 시작되면 그룹 안 모든 컨슈머가 자기 파티션을 일단 다 반납하고, 재분배가 끝날 때까지 아무도 소비를 못 해요.
컨슈머 A·B·C가 각각 파티션을 들고 잘 돌다가 컨슈머 D가 합류하면, 그 순간 A·B·C가 들고 있던 파티션을 전부 반납하고(소비 중단), 코디네이터가 A·B·C·D에게 다시 나눠줘요. 이 반납~재할당 동안 그룹 전체 처리가 멈춰요.
그리고 반납 직전에 커밋하지 못한 메시지는 재할당 후 다른 컨슈머가 다시 처리해요. 이건 수동 커밋과 멱등성 글에서 본 중복의 주요 원인이에요. 정리하면 리밸런싱이 잦을수록 처리 지연과 중복이 같이 늘어나요.
04. 파티션 할당 전략 (Assignor)
파티션을 컨슈머에 어떻게 나눌지는 partition.assignment.strategy로 정해요. 네 가지가 자주 쓰여요.
RangeAssignor와 RoundRobinAssignor를 직접 돌려 비교한 2021년 실험 기록이 Concurrency 설정 기준 글에 있어요.
RangeAssignor(기본) — 토픽별로 파티션을 범위로 잘라 할당해요. 토픽이 여러 개면 앞쪽 컨슈머에 쏠려 불균형이 생기기 쉬워요.RoundRobinAssignor— 전체 파티션을 라운드로빈으로 고르게 나눠요. 여러 토픽을 구독할 때 균형이 좋아요.StickyAssignor— 균형을 맞추면서, 리밸런싱 때 기존 할당을 최대한 유지해요. 옮기는 파티션이 줄어 비용이 낮아져요.CooperativeStickyAssignor— Sticky에 더해 협력적(incremental) 리밸런싱을 해요. 전체를 멈추지 않고 옮길 파티션만 점진적으로 재배치해요.
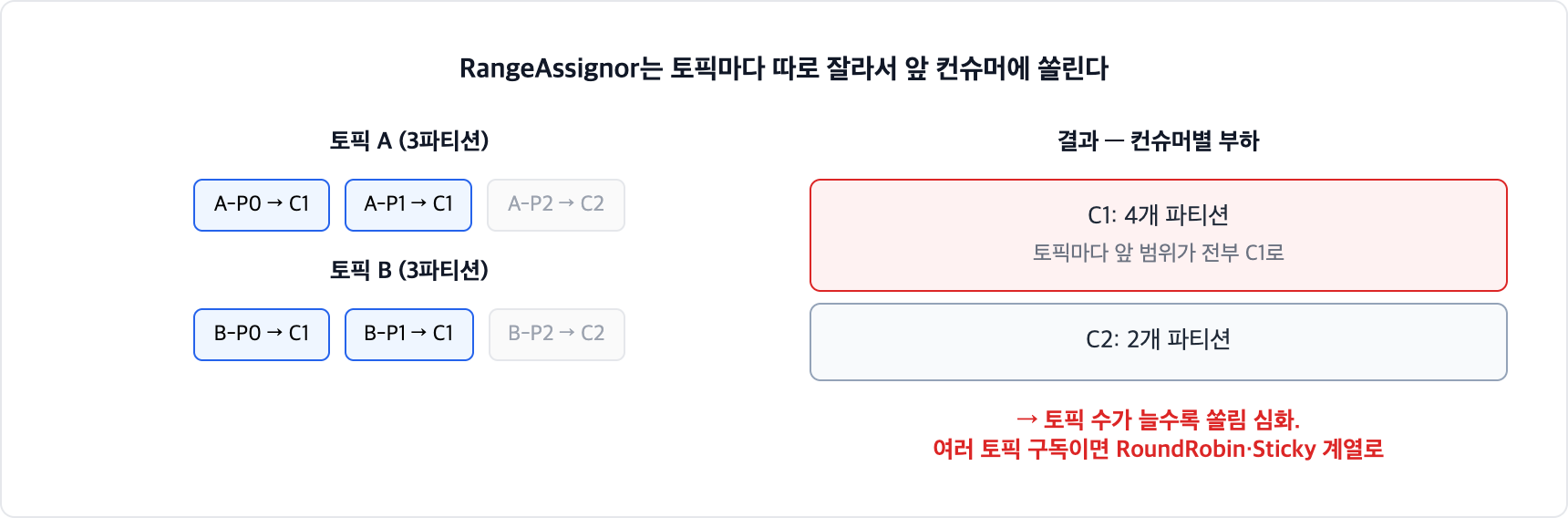
토픽 2개(각 3파티션)를 컨슈머 2개가 구독하면, RangeAssignor는 토픽마다 따로 범위를 나누니 각 토픽의 앞쪽 파티션이 첫 컨슈머에 몰려요. 컨슈머 1이 4개, 컨슈머 2가 2개처럼요. 토픽 수가 많아질수록 이 쏠림이 커지니, 여러 토픽을 구독하면 RoundRobin이나 Sticky가 나아요.
05. eager vs cooperative 리밸런싱
같은 리밸런싱이라도 방식이 두 가지예요. 이 차이가 멈춤 시간을 크게 좌우해요.

- eager (Range·RoundRobin·Sticky) — 일단 전부 반납하고 다시 받아요. 그래서 재할당 동안 전체가 멈춰요.
- cooperative (CooperativeSticky) — 옮길 필요가 없는 파티션은 계속 들고 있고, 옮겨야 하는 것만 반납해요. 멈추는 범위가 훨씬 작아요.
그래서 stop-the-world를 피하려면 CooperativeStickyAssignor가 사실상 권장이에요. 컨슈머 한 대가 들고 나도, 영향받지 않는 다른 컨슈머는 멈추지 않고 계속 처리해요.
운영 중 전환할 때 함정이 있어요. eager 계열과 cooperative 계열은 프로토콜이 달라서, 한 그룹 안에 섞이면 안 돼요. 무중단 롤링으로 바꾸려면 두 단계가 필요해요 — 먼저 전략 목록에 둘 다 넣고(예: CooperativeStickyAssignor,RangeAssignor) 전체 배포, 그다음 옛 전략을 빼고 한 번 더 배포. 한 번에 갈아끼우면 그룹 전원이 내려갔다 올라와야 해요.
06. 리밸런싱 줄이기
리밸런싱 자체를 없앨 순 없지만, 빈도와 비용은 줄일 수 있어요. 네 가지를 같이 쓰면 효과가 커요.
CooperativeStickyAssignor 사용
eager의 stop-the-world를 incremental로 바꿔요. 가장 효과가 큰 한 줄이에요.
spring:
kafka:
consumer:
properties:
partition.assignment.strategy: org.apache.kafka.clients.consumer.CooperativeStickyAssignorstatic membership
컨슈머에 group.instance.id를 부여하면, 재시작해도 같은 멤버로 인식돼 리밸런싱을 건너뛰어요. 배포 때 잠깐 내려갔다 올라오는 정도는 리밸런싱 없이 넘어가요.
spring:
kafka:
consumer:
properties:
group.instance.id: order-consumer-1 # 인스턴스마다 고유static membership의 함정. "재시작해도 같은 멤버"로 봐주는 기준이 session.timeout.ms라서, 이 안에 돌아와야 리밸런싱을 건너뛰어요. 그래서 배포 시간에 맞춰 이 값을 늘려 잡는 경우가 많은데, 늘린 만큼 진짜 죽은 인스턴스의 감지도 늦어져요. 그 파티션은 그동안 아무도 처리 안 하고요. "배포는 조용히, 장애는 빨리"가 서로 당기는 값이라 배포 소요 시간 기준으로만 적당히 늘려야 해요.
max.poll 튜닝
처리가 느려 추방되지 않게 조절해요. 한 번에 가져오는 양을 줄이거나(max.poll.records), 허용 간격을 늘려요(max.poll.interval.ms). 보통은 records를 줄이는 게 먼저예요. 한 묶음을 빨리 처리하고 자주 poll로 돌아오게 만드는 거죠.
RebalanceListener로 커밋 flush
파티션을 반납하기 직전에 처리한 오프셋을 커밋해두면, 재할당 후 중복 처리를 줄일 수 있어요.
containerProps.setConsumerRebalanceListener(new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 파티션 반납 직전: 처리한 오프셋 커밋 flush
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 새 파티션 할당 직후: 필요한 초기화
}
});07. 자주 만나는 문제
배포할 때마다 처리가 뚝뚝 끊겨요
배포 시 인스턴스가 내려갔다 올라오며 리밸런싱이 두 번 일어나는 거예요. group.instance.id static membership과 CooperativeSticky를 같이 쓰면 멈춤이 크게 줄어요.
컨슈머가 주기적으로 추방돼요
처리가 max.poll.interval.ms를 넘는 거예요. 로그에 "leaving group" 같은 메시지가 보여요. max.poll.records를 줄여 한 묶음을 가볍게 만들거나, 처리 로직을 비동기로 빼는 걸 검토해요.
특정 컨슈머만 일을 많이 해요
파티션 할당이 불균형한 거예요. RangeAssignor의 쏠림일 수 있으니 RoundRobin이나 Sticky 계열로 바꿔보고, 파티션 수와 컨슈머 수의 비율도 확인해요.
정리
리밸런싱은 컨슈머 그룹이 살아 움직이는 증거이자, 잦으면 처리 멈춤과 중복을 부르는 비용이에요. 상황에 맞춰 이렇게 골라요.
- 배포·스케일로 멈춤이 잦다면 →
CooperativeStickyAssignor와group.instance.idstatic membership으로 멈춤 범위를 줄여요. - 처리가 느려 추방된다면 →
max.poll.records를 줄이거나 처리 로직을 가볍게 해 불필요한 추방을 막아요. - 특정 컨슈머만 바쁘다면 → 할당 전략을 RoundRobin·Sticky 계열로 바꾸고 파티션·컨슈머 비율을 점검해요.
배포가 잦은 서비스일수록 이 설정의 효과가 커요. @KafkaListener 설정, 수동 커밋과 멱등성에 이어, 재할당에서 실패한 메시지를 어디로 보낼지는 에러 핸들링과 DLQ에서 다뤄요.
출처: Spring for Apache Kafka — Rebalancing Listeners · Kafka — partition.assignment.strategy · Kafka — Static Membership
'백엔드' 카테고리의 다른 글
📚 같이 보면 좋은
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 일정액의 수수료를 제공받습니다."